With the development of technology and the improvement of quality of life, we have more choices for better home life. Lamps are not just lighting, but more often for us to create a different scenario atmosphere. Smart lights are an important part of the smart home, Smart voice-controlled lights, and convenience and comfort in life.
Smart voice-controlled lights are mainstream today, but many people also decorate the preferred smart home products. Smart lamp and lantern is an important part of the smart home. Smart Voice Controlled Lights and bring convenience and comfort to life, so good for smart home. What’s the principle of smart voice-controlled lights? The following we take you to explore.
What’s the principle of Smart Voice Controlled Lights?
Take the smart LED strip lights for example, smart voice-activated strip light consists of an LED strip, LED light controller, and power supply. Usually, The LED light controller is controlled by infrared with remote control, smart class is through the connection of a WiFi LED controller or Bluetooth LED controller, using smartphones for a controller, but also through remote control and voice control.
Let the strip light into “smart”, mainly by the LED light controller. This LED light controller requires a WiFi module inside. This module needs to access a cloud and then the cloud-connected to the most popular voice control terminal in the United States – Amazon’s Alexa or Google Home for control.
Smart Voice Controlled Lights are lights controlled by voice, which belong to the category of smart lights. It is a new smart device featuring control, lighting effects, creation, sharing, light and music interaction, and light to enhance health and happiness. Smart Voice Controlled Lights are the same as other lights, only with more voice control functions. That is, by speaking you can switch on and off the light, adjust the brightness, change the color, etc.
The working principle of Smart Voice Controlled Lights
Through voice to text and then use the text (data) to control the hardware to achieve the corresponding purpose, such as control the light on and off, the light color change and brightness adjustment, etc..
Voice-activated lights uses voice recognition technology, artificial intelligence technology, lamps, and lanterns multi-party technology cross-fertilization.
The voice acquisition module mainly completes the functions of signal conditioning and signal acquisition, etc. It converts the original voice signal into a voice pulse sequence, so it mainly includes signal processing processes such as acoustic/electrical conversion, signal conditioning, and sampling.
The technical principle of speech recognition.
First of all, we know that sound is a wave. Common formats such as mp3 are compressed formats and must be converted to uncompressed pure waveform files, such as Windows PCM files, commonly known as wav files. Wav files store, in addition to a file header, a single point of the sound waveform. The figure below is an example of a waveform.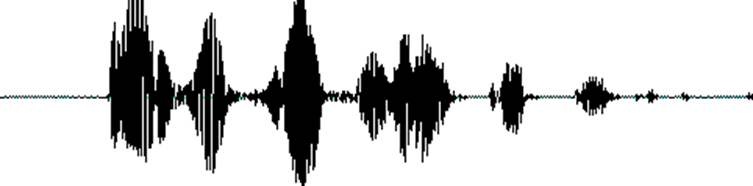
Before starting speech recognition, it is sometimes necessary to remove the mute from the beginning and end to reduce the interference caused by the subsequent steps. This mute removal operation is generally known as VAD, and requires some techniques of signal processing.
To analyze the sound, it is necessary to frame the sound, i.e., to cut the sound into small segments – small segments, each segment being called a – frame. The frame-splitting operation is generally not a simple cut, but is implemented using a moving window function, which is not described in detail here. The frames are generally overlapped with each other, as in the figure below: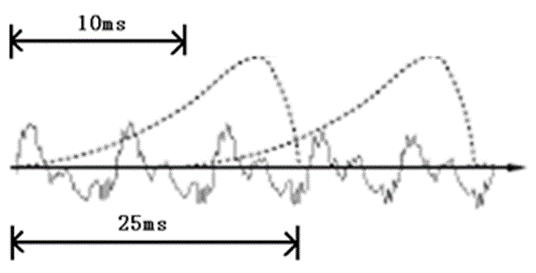
In this figure, each frame is 25 ms long, and there is an overlap of 25-10=15 ms between every two frames. We call this frame splitting with a frame length of 25ms and a frame shift of 10ms.
After framing, the speech becomes many small segments. However, the waveform has almost no descriptive power in the time domain, so the waveform must be transformed.
A common transformation method is to extract MFCC features based on the physiological characteristics of the human ear and turn each waveform into a multi-dimensional vector, which can be simply understood as a vector containing the content information of the speech frame.
This process is called acoustic feature extraction. In practice, there are many details in this step, and there are more acoustic features than just MFCC. At this point, the voice becomes a matrix with 12 rows (assuming the acoustic features are 12-dimensional) and N columns, called the observation sequence, where N is the total number of frames.
The observation sequence is shown in the figure below. Where a 12-dimensional vector represents each frame, and the color shades of the color blocks indicate the. The color of the blocks indicates the size of the vector value.
How to turn this matrix into text?
First of all, we need to introduce two concepts:
Phonemes: The pronunciation of a word is made up of phonemes. For English, a common phoneme set is the 39-phoneme set from Carnegie Mellon University, see The CMU Pronouncing Dictionary.
State: This is understood as a more detailed unit of speech than a phoneme. Usually, a phoneme is divided into 3 states.
How does speech recognition work?
Actually, it is not a mystery at all, it is just: Identify frames into states (the hard part). Combine states into phonemes. Combine phonemes into words. The following diagram shows this.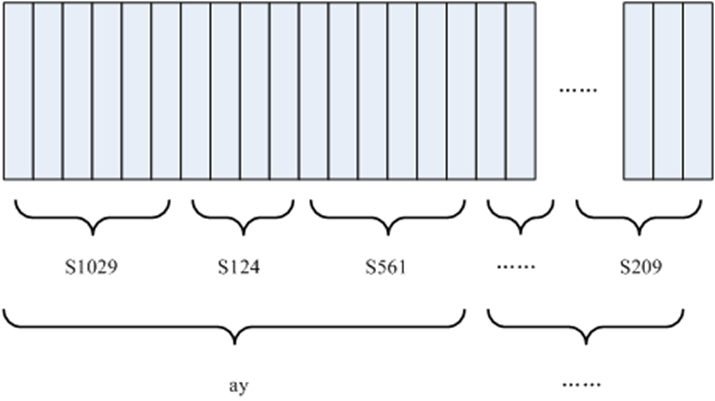
In the diagram, each vertical bar represents a frame, several frames correspond to a state, every three states are combined into a phoneme, and a thousand phonemes are combined into a word. In other words, as long as we know which state each frame corresponds to, the result of speech recognition is also available.
What is the state of each phoneme?
There is an easy way to see which state a frame corresponds to with the highest probability, and then the frame belongs to which state. For example, in the diagram below, the frame has the highest probability of being in state S3, so we guess that the frame belongs to state S3.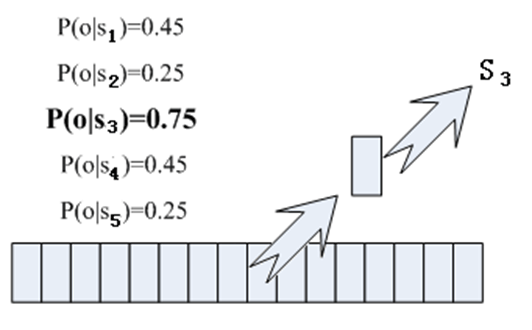
Where are the probabilities used read from?
There is something called the “acoustic model”, which stores a large set of parameters through which the probabilities of frames and states can be known. The method to obtain this large set of parameters is called “training” and requires the use of a huge amount of speech data.
There is a problem with: each frame will get a state number, and finally, the whole speech will get a bunch of messy state numbers. Suppose there are 1000 frames of speech, each frame corresponds to 1 state, and every 3 states are combined into one phoneme, then there are about 300 phonemes, but there are not that many phonemes in this speech. If we do this, the state numbers may not be combined into phonemes at all.
It makes sense that the states of adjacent frames should be mostly the same since each frame is very short.
A common way to solve this problem is to use the Hidden Markov Model (HMM).
1.In the first step, a state network is constructed.
2.In the second step, the path that best matches the sound is found from the state network.
This limits the results to a predefined network, which avoids the problem mentioned earlier. Also brings a limitation;
For example, if the network you set only contains the state paths of the sentences, “It’s sunny today” and “It’s raining today”, then no matter what is said, the result is bound to be The result will be one of these two sentences.
What if you want to recognize arbitrary text?
Build the network large enough to contain the paths of any text. But the larger the network is, the harder it is to achieve a better recognition accuracy. Therefore, we need to choose the network size and structure according to the actual task requirements.
To build a state network, the word-level network is expanded into a phoneme network, and then into a state network. The process of speech recognition is actually to search for an optimal path in the state network, which has the highest probability of corresponding to the speech, which is called “decoding”. The path search algorithm is a dynamic planning pruning algorithm called Viterbi algorithm, which is used to find the global optimal path.
The cumulative probability here is composed of three parts, which are:
- Observation probability: the probability corresponding to each frame and each state
- Transfer probability: the probability that each state is transferred to itself or to the next state
- Language probability: the probability obtained from the statistical law of language
The first two probabilities are obtained from the acoustic model, and the last one is obtained from the language model. The language model is trained using a large amount of text, and the statistical laws of a language itself can be used to help improve the correct recognition rate.
We are top LED light controller and voice controlled lights manufacturer in China, If you are looking for LED light controller, Get in touch with us to arrange a consultation.